
“In my head, I churn over every sentence 10 times, delete a word, add an adjective, and learn my text by heart, paragraph by paragraph,” Jean-Dominique Bauby wrote in his memoir, The Diving Bell and the Butterfly. In the book, Bauby, a journalist and editor, recalled his life before and after a paralysing spinal injury that left him virtually unable to move a muscle; he tapped out the book letter by letter, by blinking an eyelid.
Thousands of people are reduced to similarly painstaking means of communication as a result of injuries suffered in accidents or combat, of strokes, or of neurodegenerative disorders like amyotrophic lateral sclerosis, or ALS, that disable the ability to speak.
Now, scientists are reporting they have developed a virtual prosthetic voice, a system that decodes the brain's vocal intentions and translates them into mostly understandable speech, with no need to move a muscle, even those in the mouth. (The physicist and author Stephen Hawking used a muscle in his cheek to type keyboard characters, which a computer synthesised into speech.)
"It's formidable work, and it moves us up another level toward restoring speech" by decoding brain signals, says Dr Anthony Ritaccio, a neurologist and neuroscientist at the Mayo Clinic in Jacksonville, Florida, who was not a member of the research group.
Researchers have developed other virtual speech aids. Those work by decoding the brain signals responsible for recognising letters and words, the verbal representations of speech. But those approaches lack the speed and fluidity of natural speaking.
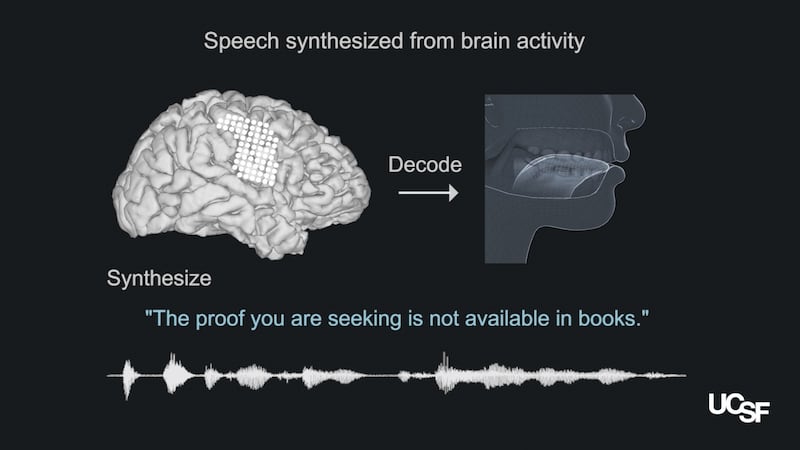
The new system, described in the journal Nature, decipher the brain’s motor commands guiding vocal movement during speech – the tap of the tongue, the narrowing of the lips – and generates intelligible sentences that approximate a speaker’s natural cadence.
‘Proof of principle’
Experts say the new work represents a “proof of principle”, a preview of what may be possible after further experimentation and refinement. The system was tested on people who speak normally; it has not been tested in people whose neurological conditions or injuries, like common strokes, could make the decoding difficult or impossible.
For the new trial, scientists at the University of California, San Francisco, and UC Berkeley recruited five people who were in the hospital being evaluated for epilepsy surgery.
Many people with epilepsy do poorly on medication and opt to undergo brain surgery. Before operating, doctors must first locate the “hot spot” in each person’s brain where the seizures originate; this is done with electrodes that are placed in the brain, or on its surface, and listen for telltale electrical storms.
Pinpointing this location can take weeks. In the interim, patients go through their days with electrodes implanted in or near brain regions that are involved in movement and auditory signalling. These patients often consent to additional experiments that piggyback on those implants.
The five such patients at UCSF agreed to test the virtual voice generator. Each had been implanted with one or two electrode arrays: stamp-size pads, containing hundreds of tiny electrodes, that were placed on the surface of the brain.
As each participant recited hundreds of sentences, the electrodes recorded the firing patterns of neurons in the motor cortex. The researchers associated those patterns with the subtle movements of the patient’s lips, tongue, larynx and jaw that occur during natural speech. The team then translated those movements into spoken sentences.
Test the fluency
Native English speakers were asked to listen to the sentences to test the fluency of the virtual voices. As much as 70 per cent of what was spoken by the virtual system was intelligible, the study found.
"We showed, by decoding the brain activity guiding articulation, we could simulate speech that is more accurate and natural sounding than synthesised speech based on extracting sound representations from the brain," says Dr Edward Chang, a professor of neurosurgery at UCSF and an author of the new study. His colleagues were Gopala K Anumanchipalli, also of UCSF, and Josh Chartier, who is affiliated with both UCSF and Berkeley.

Previous implant-based communication systems have produced about eight words a minute. The new programme generates about 150 words a minute, the pace of natural speech.
The researchers also found that a synthesised voice system based on one person’s brain activity could be used, and adapted, by someone else – an indication that off-the-shelf virtual systems could be available one day.
The team is planning to move to clinical trials to further test the system. The biggest clinical challenge may be finding suitable patients: strokes that disable a person’s speech often also damage or wipe out the areas of the brain that support speech articulation.
Still, the field of brain-machine interface technology, as it is known, is advancing rapidly, with teams around the world adding refinements that might be tailored to specific injuries.
"With continued progress," wrote Chethan Pandarinath and Yahia H Ali, biomedical engineers at Emory University and Georgia Institute of Technology, in an accompanying commentary, "we can hope that individuals with speech impairments will regain the ability to freely speak their minds and reconnect with the world around them." – New York Times










